Kódování dat
Úvod a značení
Abys mohl použít kvantový algoritmus, musí se klasická data nějakým způsobem dostat do kvantového obvodu. Tomu se obvykle říká kódování dat, někdy také načítání dat. Vzpomeň si z předchozích lekcí na pojem mapování příznaků (feature mapping), tedy mapování datových příznaků z jednoho prostoru do druhého. Pouhý přenos klasických dat do kvantového počítače je svým způsobem mapování a mohli bychom ho nazvat mapováním příznaků. V praxi vestavěná mapování příznaků v Qiskitu (jako z_feature_map a zz_feature_map) obvykle zahrnují rotační vrstvy a provázávací vrstvy, které stav rozšiřují do mnoha dimenzí v Hilbertově prostoru. Tento proces kódování je klíčovou součástí algoritmů kvantového strojového učení a přímo ovlivňuje jejich výpočetní schopnosti.
Některé z níže uvedených technik kódování lze efektivně klasicky simulovat; to je obzvlášť snadno vidět u metod kódování, které vedou k součinovým stavům (tedy neprovazují qubity). A pamatuj, že kvantová užitečnost se s největší pravděpodobností projeví tam, kde kvantově-podobná složitost datové sady dobře odpovídá metodě kódování. Proto je velmi pravděpodobné, že si nakonec budeš psát vlastní kódovací obvody. Zde ukazujeme širokou škálu možných kódovacích strategií jednoduše proto, abys je mohl porovnat a uvidět, co je možné. Existují některá velmi obecná tvrzení, která lze o užitečnosti kódovacích technik říci. Například efficient_su2 (viz níže) s úplným provázávacím schématem má mnohem větší šanci zachytit kvantové vlastnosti dat než metody, které vedou k součinovým stavům (jako z_feature_map). To ale neznamená, že efficient_su2 je dostatečné nebo dostatečně dobře sladěné s tvou datovou sadou, aby přineslo kvantové zrychlení. To vyžaduje pečlivé zvážení struktury modelovaných nebo klasifikovaných dat. Je tu také balancování s hloubkou obvodu, protože mnoho mapování příznaků, která plně provazují qubity v obvodu, vede k velmi hlubokým obvodům — příliš hlubokým na to, aby na dnešních kvantových počítačích přinesly použitelné výsledky.
Značení
Datová sada je množina datových vektorů: , kde každý vektor je -rozměrný, tedy . Toto by šlo rozšířit i na komplexní datové příznaky. V této lekci můžeme občas použít toto značení pro celou sadu a její konkrétní prvky jako . Většinou však budeme hovořit o načítání jednoho vektoru z naší datové sady po druhém a budeme jednotlivý vektor příznaků často označovat jednoduše jako .
Navíc je běžné používat symbol k označení mapování příznaků datového vektoru . Konkrétně v kvantových výpočtech je běžné odkazovat na mapování pomocí , což je značení zdůrazňující unitární povahu těchto operací. Bylo by správné použít pro oba případy stejný symbol; obojí jsou mapování příznaků. V tomto kurzu obvykle používáme:
- při obecné diskusi o mapování příznaků ve strojovém učení a
- při diskusi o obvodových implementacích mapování příznaků.
Normalizace a ztráta informace
V klasickém strojovém učení se trénovací datové příznaky často „normalizují“ neboli přeškálují, což často zlepšuje výkon modelu. Jedním běžným způsobem, jak to udělat, je použití min-max normalizace nebo standardizace. Při min-max normalizaci se sloupce příznaků datové matice (řekněme příznak ) normalizují:
kde min a max označují minimum a maximum příznaku přes datových vektorů v datové sadě . Všechny hodnoty příznaků pak spadají do jednotkového intervalu: pro všechna , .
Normalizace je také základním pojmem v kvantové mechanice a kvantových výpočtech, ale od min-max normalizace se mírně liší. Normalizace v kvantové mechanice vyžaduje, aby délka (v kontextu kvantových výpočtů 2-norma) stavového vektoru byla rovna jedné: , čímž se zajistí, že součet pravděpodobností měření je 1. Stav se normalizuje dělením 2-normou; tedy přeškálováním
V kvantových výpočtech a kvantové mechanice to není normalizace, kterou by na data uvalovali lidé, ale základní vlastnost kvantových stavů. V závislosti na tvém kódovacím schématu může toto omezení ovlivnit, jak se tvá data přeškálovávají. Například v amplitudovém kódování (viz níže) je datový vektor normalizován , jak vyžaduje kvantová mechanika, a to ovlivňuje škálování kódovaných dat. Ve fázovém kódování se doporučuje přeškálovat hodnoty příznaků tak, aby , takže nedochází ke ztrátě informace kvůli efektu modulo- při kódování do fázového úhlu qubitu[1,2].
Metody kódování
V následujících několika sekcích budeme odkazovat na malou příkladovou klasickou datovou sadu sestávající z datových vektorů, z nichž každý má příznaky:
Ve značení zavedeném výše bychom například mohli říct, že příznak datového vektoru v naší sadě je
Bázové kódování
Bázové kódování kóduje klasický -bitový řetězec do stavu výpočetní báze -qubitového systému. Vezmi si například To lze reprezentovat jako -bitový řetězec a -qubitovým systémem jako kvantový stav . Obecněji pro -bitový řetězec je odpovídající -qubitový stav s pro . Všimni si, že je to jen pro jediný příznak.
Bázové kódování v kvantových výpočtech reprezentuje každý klasický bit jako samostatný qubit, čímž se binární reprezentace dat přímo mapuje na kvantové stavy ve výpočetní bázi. Když je potřeba zakódovat více příznaků, každý příznak se nejprve převede do své binární podoby a pak se přiřadí k odlišné skupině qubitů — jedné skupině na příznak — kde každý qubit odráží bit v binární reprezentaci onoho příznaku.
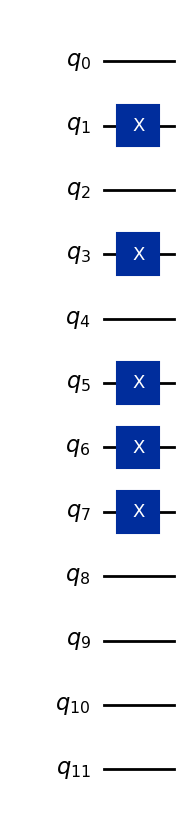
Jako příklad si zakódujme vektor (5, 7, 0).
Předpokládejme, že všechny příznaky jsou uloženy ve čtyřech bitech (více, než potřebujeme, ale dost na reprezentaci jakéhokoli celého čísla, které je v desítkové soustavě jednociferné):
5 → binárně 0101
7 → binárně 0111
0 → binárně 0000
Tyto bitové řetězce jsou přiřazeny třem sadám čtyř qubitů, takže celkový 12-qubitový bázový stav je:
Zde první čtyři qubity reprezentují první příznak, následující čtyři qubity druhý příznak a poslední čtyři qubity třetí příznak. Kód níže převádí datový vektor (5,7,0) na kvantový stav a je zobecněn tak, aby to dělal i pro jiné jednociferné příznaky.
# Added by doQumentation — required packages for this notebook
!pip install -q matplotlib numpy qiskit
from qiskit import QuantumCircuit
# Data point to encode
x = 5 # binary: 0101
y = 7 # binary: 0111
z = 0 # binary: 0000
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, "04b")] # [0,1,0,1]
y_bits = [int(b) for b in format(y, "04b")] # [0,1,1,1]
z_bits = [int(b) for b in format(z, "04b")] # [0,0,0,0]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,1,0,1,1,1,0,0,0,0]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw("mpl")
Ověřte si porozumění
Přečti si otázku níže, zamysli se nad odpovědí a poté klikni na trojúhelník, abys odhalil řešení.
Napiš kód, který zakóduje první vektor v naší ukázkové datové sadě :
pomocí basis encoding.
Odpověď:
import math
from qiskit import QuantumCircuit
# Data point to encode
x = 4 # binary: 0100
y = 8 # binary: 1000
z = 5 # binary: 0101
# Convert each to 4-bit binary list
x_bits = [int(b) for b in format(x, '04b')] # [0,1,0,0]
y_bits = [int(b) for b in format(y, '04b')] # [1,0,0,0]
z_bits = [int(b) for b in format(z, '04b')] # [0,1,0,1]
# Combine all bits
all_bits = x_bits + y_bits + z_bits # [0,1,0,0,1,0,0,0,0,1,0,1]
# Initialize a 12-qubit quantum circuit
qc = QuantumCircuit(12)
# Apply x-gates where the bit is 1
for idx, bit in enumerate(all_bits):
if bit == 1:
qc.x(idx)
qc.draw('mpl')
Amplitudové kódování
Amplitudové kódování kóduje data do amplitud kvantového stavu. Reprezentuje normalizovaný klasický -rozměrný datový vektor jako amplitudy -qubitového kvantového stavu :
kde je stejná dimenze datových vektorů jako dříve, je prvek a je stav výpočetní báze. Zde je normalizační konstanta, která se určí z kódovaných dat. Toto je normalizační podmínka uložená kvantovou mechanikou:
Obecně se jedná o jinou podmínku než min/max normalizaci použitou pro každý příznak napříč všemi datovými vektory. Jak přesně se s tím vypořádáš, bude záviset na tvém problému. Ale výše uvedenou kvantově mechanickou normalizační podmínku nelze obejít.
V amplitudovém kódování je každý příznak v datovém vektoru uložen jako amplituda jiného kvantového stavu. Protože systém qubitů poskytuje amplitud, amplitudové kódování příznaků vyžaduje qubitů.
Jako příklad zakódujme první vektor v naší ukázkové datové sadě , , pomocí amplitudového kódování. Po normalizaci výsledného vektoru dostaneme:
a výsledný 2-qubitový kvantový stav by byl:
Ve výše uvedeném příkladu není počet příznaků ve vektoru mocninou 2. Když není mocnina 2, jednoduše zvolíme hodnotu počtu qubitů takovou, že , a doplníme vektor amplitud neinformativními konstantami (zde nulou).
Stejně jako u basis encoding, jakmile vypočítáme, jaký stav zakóduje naši datovou sadu, v Qiskitu můžeme použít funkci initialize k jeho přípravě:
import math
desired_state = [
1 / math.sqrt(105) * 4,
1 / math.sqrt(105) * 8,
1 / math.sqrt(105) * 5,
1 / math.sqrt(105) * 0,
]
qc = QuantumCircuit(2)
qc.initialize(desired_state, [0, 1])
qc.decompose(reps=5).draw(output="mpl")

Výhodou amplitudového kódování je výše zmíněný požadavek pouze qubitů pro zakódování. Následné algoritmy však musí operovat na amplitudách kvantového stavu a metody pro přípravu a měření kvantových stavů obvykle nejsou efektivní.
Ověřte si porozumění
Přečti si otázky níže, zamysli se nad odpověďmi a poté klikni na trojúhelníky pro zobrazení řešení.
Zapiš normalizovaný stav pro zakódování následujícího vektoru (složeného ze dvou vektorů z našeho ukázkového datasetu):
pomocí amplitudového kódování.
Odpověď:
Abychom zakódovali 6 čísel, potřebujeme mít k dispozici alespoň 6 stavů, na jejichž amplitudy lze data zakódovat. To bude vyžadovat 3 qubity. Pomocí neznámého normalizačního faktoru to lze zapsat takto:
Všimni si, že
Tedy nakonec,
Pro stejný datový vektor napiš kód pro vytvoření obvod, který načte tyto datové příznaky pomocí amplitudového kódování.
Odpověď:
desired_state = [
9 / math.sqrt(270),
8 / math.sqrt(270),
6 / math.sqrt(270),
2 / math.sqrt(270),
9 / math.sqrt(270),
2 / math.sqrt(270),
0,
0,
]
print(desired_state)
qc = QuantumCircuit(3)
qc.initialize(desired_state, [0, 1, 2])
qc.decompose(reps=8).draw(output="mpl")
[0.5477225575051662, 0.48686449556014766, 0.36514837167011077, 0.12171612389003691, 0.5477225575051662, 0.12171612389003691, 0, 0]

Může se stát, že budeš muset pracovat s velmi velkými datovými vektory. Uvažuj vektor
Napiš kód pro automatizaci normalizace a vygeneruj kvantový obvod pro amplitudové kódování.
Odpověď:
Existuje mnoho možných odpovědí. Zde je kód, který v průběhu vytiskne několik mezikroků:
import numpy as np
from math import sqrt
init_list = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5]
qubits = round(np.log(len(init_list)) / np.log(2) + 0.4999999999)
need_length = 2**qubits
pad = need_length - len(init_list)
for i in range(0, pad):
init_list.append(0)
init_array = np.array(init_list) # Unnormalized data vector
length = sqrt(
sum(init_array[i] ** 2 for i in range(0, len(init_array)))
) # Vector length
norm_array = init_array / length # Normalized array
print("Normalized array:")
print(norm_array)
print()
qubit_numbers = []
for i in range(0, qubits):
qubit_numbers.append(i)
print(qubit_numbers)
qc = QuantumCircuit(qubits)
qc.initialize(norm_array, qubit_numbers)
qc.decompose(reps=7).draw(output="mpl")
Normalized array: [0.17342199 0.34684399 0.21677749 0.39019949 0.34684399 0.26013299 0.086711 0.39019949 0.086711 0.21677749 0.30348849 0. 0.1300665 0.30348849 0.21677749 0. ]
[0, 1, 2, 3]
Vidíš výhody amplitudového kódování oproti bázovému kódování? Pokud ano, vysvětli je.
Odpověď:
Možných odpovědí může být více. Jedna z nich je, že díky pevnému pořadí bázových stavů toto amplitudové kódování zachovává pořadí zakódovaných čísel. Bývá také obvykle zakódováno hustěji.
Výhodou amplitudového kódování je, že pro -dimenzionální (-příznaková) datový vektor jsou potřeba pouze qubitů. Amplitudové kódování je však obecně neefektivní postup, který vyžaduje přípravu libovolného stavu, což je exponenciální z hlediska počtu CNOT hradlo. Jinak řečeno, příprava stavu má polynomiální složitost běhu v počtu dimenzí, kde a je počet qubitů. Amplitudové kódování „poskytuje exponenciální úsporu v prostoru za cenu exponenciálního nárůstu v čase"[3]; v určitých případech jsou však dosažitelné nárůsty doby běhu na [4]. Pro end-to-end kvantové urychlení je třeba vzít v úvahu složitost běhu načítání dat.
Úhlové kódování
Úhlové kódování je zajímavé pro mnoho QML modelů používajících Pauliho příznakové mapy, jako jsou kvantové podpůrné vektorové stroje (QSVM) a variační kvantové obvody (VQC), mimo jiné. Úhlové kódování úzce souvisí s fázovým kódováním a hustým úhlovým kódováním, která jsou představena níže. Zde budeme používat pojem „úhlové kódování" ve smyslu rotace v , tedy rotace odklánějící se od osy , které lze dosáhnout například pomocí hradlo nebo hradlo [1,3]. Ve skutečnosti lze data zakódovat do libovolné rotace nebo kombinace rotací. Nicméně je v literatuře běžné, proto jej zde zdůrazňujeme.
Při aplikaci na jediný qubit provede úhlové kódování rotaci kolem osy Y úměrnou hodnotě dat. Uvažujme kódování jediného () příznaku z datového vektoru v datové sadě, :
Alternativně lze úhlové kódování provést pomocí hradlo , zakódovaný stav by však měl komplexní relativní fázi oproti .
Úhlové kódování se od dvou předchozích metod liší v několika ohledech. V úhlovém kódování platí:
- Každá hodnota příznaku je namapována na odpovídající qubit, , přičemž qubitům zůstává produktový stav.
- V jednom okamžiku je zakódována jedna číselná hodnota, nikoli celá sada příznaků z datového bodu.
- Pro datových příznaků je potřeba qubitů, kde . Rovnost zde platí velmi často. V dalších oddílech uvidíme, jak je možné .
- Výsledný obvod má konstantní hloubku (typicky hloubku 1 před transpilací).
Kvantový obvod s konstantní hloubkou je obzvlášť vhodný pro současný kvantový hardware. Další vlastností kódování dat pomocí (a konkrétně naší volby úhlového kódování kolem osy Y) je, že vytváří reálně hodnotové kvantové stavy, které mohou být užitečné pro určité aplikace. Pro rotaci kolem osy Y jsou data mapována pomocí hradlo s reálně hodnotovým úhlem (Qiskit RYGate). Stejně jako u fázového kódování (viz níže) doporučujeme data přeškálovat tak, aby , čímž předejdeme ztrátě informací a jiným nežádoucím efektům.
Následující kód v Qiskitu otočí jediný qubit z počátečního stavu a zakóduje hodnotu dat .
from qiskit.quantum_info import Statevector
from math import pi
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
Definujeme funkci pro vizualizaci akce na stavovém vektoru. Detaily definice funkce nejsou důležité, ale schopnost vizualizovat stavové vektory a jejich změny je podstatná.
import numpy as np
from qiskit.visualization.bloch import Bloch
from qiskit.visualization.state_visualization import _bloch_multivector_data
def plot_Nstates(states, axis, plot_trace_points=True):
"""This function plots N states to 1 Bloch sphere"""
bloch_vecs = [_bloch_multivector_data(s)[0] for s in states]
if axis is None:
bloch_plot = Bloch()
else:
bloch_plot = Bloch(axes=axis)
bloch_plot.add_vectors(bloch_vecs)
if len(states) > 1:
def rgba_map(x, num):
g = (0.95 - 0.05) / (num - 1)
i = 0.95 - g * num
y = g * x + i
return (0.0, y, 0.0, 0.7)
num = len(states)
bloch_plot.vector_color = [rgba_map(x, num) for x in range(1, num + 1)]
bloch_plot.vector_width = 3
bloch_plot.vector_style = "simple"
if plot_trace_points:
def trace_points(bloch_vec1, bloch_vec2):
# bloch_vec = (x,y,z)
n_points = 15
thetas = np.arccos([bloch_vec1[2], bloch_vec2[2]])
phis = np.arctan2(
[bloch_vec1[1], bloch_vec2[1]], [bloch_vec1[0], bloch_vec2[0]]
)
if phis[1] < 0:
phis[1] = phis[1] + 2 * pi
angles0 = np.linspace(phis[0], phis[1], n_points)
angles1 = np.linspace(thetas[0], thetas[1], n_points)
xp = np.cos(angles0) * np.sin(angles1)
yp = np.sin(angles0) * np.sin(angles1)
zp = np.cos(angles1)
pnts = [xp, yp, zp]
bloch_plot.add_points(pnts)
bloch_plot.point_color = "k"
bloch_plot.point_size = [4] * len(bloch_plot.points)
bloch_plot.point_marker = ["o"]
for i in range(len(bloch_vecs) - 1):
trace_points(bloch_vecs[i], bloch_vecs[i + 1])
bloch_plot.sphere_alpha = 0.05
bloch_plot.frame_alpha = 0.15
bloch_plot.figsize = [4, 4]
bloch_plot.render()
plot_Nstates(states, axis=None, plot_trace_points=True)

To byl pouze jediný příznak jediného datového vektoru. Při kódování příznaků do rotačních úhlů qubitů, řekněme pro datový vektor bude zakódovaný produktový stav vypadat takto:
Poznamenejme, že to je ekvivalentní
Ověř si své znalosti
Přečti si otázky níže, přemýšlej o svých odpovědích a pak klikni na trojúhelníky pro zobrazení řešení.
Zakóduj datový vektor pomocí úhlového kódování, jak je popsáno výše.
Odpověď:
qc = QuantumCircuit(3)
qc.ry(0, 0)
qc.ry(2 * math.pi / 4, 1)
qc.ry(2 * math.pi / 2, 2)
qc.draw(output="mpl")

Kolik qubitů je při úhlovém kódování, jak je popsáno výše, potřeba pro zakódování 5 příznaků?
Odpověď: 5
Fázové kódování
Fázové kódování je velmi podobné výše popsanému úhlovému kódování. Fázový úhel qubitu je reálně hodnotný úhel kolem osy od osy +. Data jsou mapována pomocí fázové rotace , kde (více informací viz Qiskit PhaseGate). Doporučuje se přeškálovat data tak, aby . Předejdeš tím ztrátě informací a dalším potenciálně nežádoucím efektům[1,2].
qubit je často inicializován ve stavu , který je vlastním stavem operátoru fázové rotace, což znamená, že stav qubitu je nejprve potřeba otočit, aby bylo možné fázové kódování implementovat. Proto dává smysl inicializovat stav Hadamardovým hradlo: . Fázové kódování na jednom qubitu znamená udělení relativní fáze úměrné hodnotě dat:
Postup fázového kódování mapuje každou hodnotu příznaku na fázi odpovídajícího qubitu, . Celkově má fázové kódování hloubku obvod 2, včetně Hadamardovy vrstvy, což z něj činí efektivní schéma kódování. Fázově zakódovaný vícequbitový stav ( qubitů pro příznaků) je produktový stav:
Následující kód v Qiskit nejprve připraví počáteční stav jednoho qubitu jeho otočením Hadamardovým hradlo, a poté ho znovu otočí pomocí phase gate, aby zakódoval datový příznak .
qc = QuantumCircuit(1)
qc.h(0) # Hadamard gate rotates state down to Bloch equator
state1 = Statevector.from_instruction(qc)
qc.p(pi / 2, 0) # Phase gate rotates by an angle pi/2
state2 = Statevector.from_instruction(qc)
states = state1, state2
qc.draw("mpl", scale=1)

Rotaci v můžeme vizualizovat pomocí funkce plot_Nstates, kterou jsme definovali.
plot_Nstates(states, axis=None, plot_trace_points=True)

Graf Blochovy sféry zobrazuje rotaci kolem osy Z , kde . Světle zelená šipka znázorňuje výsledný stav.
Fázové kódování se používá v mnoha kvantových příznakovýkch mapách, zejména ve a příznakových mapách a obecných Pauliho příznakových mapách a dalších.
Zkontroluj si porozumění
Přečti si níže uvedené otázky, zamysli se nad svými odpověďmi a pak klikni na trojúhelníky, aby se zobrazila řešení.
Kolik qubitů je potřeba k tomu, aby bylo možné pomocí výše popsaného fázového kódování uložit 8 příznaků?
Odpověď: 8
Napiš kód pro vektor pomocí fázového kódování.
Odpověď:
Možných odpovědí může být mnoho. Zde je jeden příklad:
phase_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0]
qc = QuantumCircuit(len(phase_data))
for i in range(0, len(phase_data)):
qc.h(i)
qc.rz(phase_data[i] * 2 * math.pi / float(max(phase_data)), i)
qc.draw(output="mpl")

Husté úhlové kódování
Husté úhlové kódování (DAE) je kombinací úhlového kódování a fázového kódování. DAE umožňuje zakódovat dvě hodnoty příznaků do jednoho qubitu: jeden úhel pomocí rotace kolem osy Y a druhý pomocí rotace kolem osy : . Zakóduje dva příznaky takto:
Zakódování dvou datových příznaků do jednoho qubitu vede ke snížení počtu qubitů potřebných pro kódování. Po rozšíření na více příznaků lze datový vektor zakódovat jako:
DAE lze zobecnit na libovolné funkce dvou příznaků namísto zde použitých goniometrických funkcí. Tato metoda se nazývá obecné qubitové kódování[7].
Jako příklad DAE kód níže zakóduje a vizualizuje kódování příznaků a .
qc = QuantumCircuit(1)
state1 = Statevector.from_instruction(qc)
qc.ry(3 * pi / 8, 0)
state2 = Statevector.from_instruction(qc)
qc.rz(7 * pi / 4, 0)
state3 = Statevector.from_instruction(qc)
states = state1, state2, state3
plot_Nstates(states, axis=None, plot_trace_points=True)

Ověř si své znalosti
Přečti si níže uvedené otázky, zamysli se nad odpověďmi a pak klikni na trojúhelníky pro zobrazení řešení.
Kolik qubitů je potřeba k zakódování 6 příznaků pomocí hustého kódování?
Odpověď: 3
Napiš kód pro načtení vektoru pomocí hustého úhlového kódování.
Odpověď:
Všimni si, že jsme seznam doplnili nulou „0", abychom se vyhnuli problému s jedním nevyužitým parametrem v našem schématu kódování.
dense_data = [4, 8, 5, 9, 8, 6, 2, 9, 2, 5, 7, 0, 3, 7, 5, 0]
qc = QuantumCircuit(int(len(dense_data) / 2))
entry = 0
for i in range(0, int(len(dense_data) / 2)):
qc.ry(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.rz(dense_data[entry] * 2 * math.pi / float(max(dense_data)), i)
entry = entry + 1
qc.draw(output="mpl")

Kódování s vestavěnými mapami příznaků
Kódování v libovolných bodech
Úhlové kódování, fázové kódování a husté kódování připravovaly produktové stavy s příznakem zakódovaným na každém qubitu (nebo dvěma příznaky na qubit). To se liší od bázového kódování a amplitudového kódování v tom, že tyto metody využívají provázané stavy. Mezi datovým příznakem a qubitem neexistuje vztah 1:1. Například při amplitudovém kódování může být jeden příznak amplitudou stavu a jiný příznak amplitudou pro . Obecně platí, že metody kódující do produktových stavů dávají mělčí obvod a mohou uložit 1 nebo 2 příznaky na každý qubit. Metody využívající provázání a spojující příznak se stavem spíše než s qubitem vedou k hlubším obvod a mohou průměrně uložit více příznaků na qubit.
Kódování však nemusí být zcela v produktových stavech ani zcela v provázaných stavech jako při amplitudovém kódování. Mnohá kódovací schémata vestavěná v Qiskitu skutečně umožňují kódování jak před, tak po vrstvě provázání, nikoli jen na začátku. Toto se označuje jako „data reuploading". Pro související práce viz reference [5] a [6].
V této části použijeme a vizualizujeme několik vestavěných kódovacích schémat. Všechny metody v této části kódují příznaků jako rotace na parametrizovaných hradlo na qubitech, kde . Všimni si, že maximalizace načítání dat pro daný počet qubitů není jediným kritériem. V mnoha případech může být hloubka obvod ještě důležitějším faktorem než počet qubitů.
Efficient SU2
Běžným a užitečným příkladem kódování s provázáním je Qiskitův obvod efficient_su2. Pozoruhodné je, že tento obvod dokáže například zakódovat 8 příznaků na pouhé 2 qubity. Podívejme se na to a pak se pokusme pochopit, jak je to možné.
from qiskit.circuit.library import efficient_su2
circuit = efficient_su2(num_qubits=2, reps=1, insert_barriers=True)
circuit.decompose().draw(output="mpl")

Při zápisu stavů budeme používat Qiskitovu konvenci, že qubity s nejnižší váhou jsou seřazeny zcela vpravo, jak je tomu v nebo Tyto stavy se mohou velmi rychle stát velmi složitými, a tento vzácný příklad může pomoci vysvětlit, proč se takové stavy zřídka zapisují explicitně.
Náš systém začíná ve stavu Až po první bariéru (bod, který označujeme ), jsou naše stavy:
To je jen husté kódování, které jsme viděli dříve. Nyní po hradlo CNOT, na druhé bariéře (), je náš stav
Nyní použijeme poslední sadu jednoqubitových rotací a seskupíme stejné stavy, abychom získali:
To je pravděpodobně příliš složité na to, aby se to dalo snadno přečíst. Místo toho se jen zamysli nad tím, kolik parametrů jsme do stavu načetli: osm. Máme však jen čtyři výpočetní bázové stavy. Na první pohled se může zdát, že jsme načetli více parametrů, než dává smysl, protože finální stav lze zapsat jako . Všimni si však, že každý prefaktor je komplexní! Zapsáno takto:
Vidíme, že na stavu skutečně máme osm parametrů, na které lze zakódovat osm příznaků.
Zvýšením počtu qubitů a zvýšením počtu opakování vrstev provázání a rotací lze zakódovat mnohem více dat. Vypisování vlnových funkcí se rychle stává nezvladatelným. Stále však můžeme kódování sledovat v praxi.
Zde zakódujeme datový vektor s 12 příznaky na 3-qubitový obvod efficient_su2, přičemž každý parametrizovaný hradlo použijeme k zakódování jiného příznaku.
V tomto datovém vektoru jsou příznaky zobrazeny v určitém pořadí. Samotné o sobě nezáleží na tom, zda jsou zakódovány v tomto pořadí nebo v opačném. Důležité je sledovat to a být konzistentní. Všimni si v diagramu obvodu, že efficient_su2 předpokládá určité pořadí kódování, konkrétně vyplňuje první vrstvu parametrizovaných hradlo od qubitu 0 do qubitu 2 a poté přechází na další vrstvu. To není ani konzistentní, ani nekonzistentní s little-endian zápisem, protože zde datové příznaky nelze seřadit podle qubitu a priori, před tím, než je specifikován kódovací obvod.
x = [0.1, 0.2, 0.3, 0.4, 0.5, 0.6, 0.7, 0.8, 0.9, 1.0, 1.1, 1.2]
circuit = efficient_su2(num_qubits=3, reps=1, insert_barriers=True)
encode = circuit.assign_parameters(x)
encode.decompose().draw(output="mpl")

Místo zvyšování počtu qubitů se můžeš rozhodnout zvýšit počet opakování vrstev provázání a rotací. Existují však limity toho, kolik opakování je užitečných. Jak bylo uvedeno dříve, existuje kompromis: obvod s více qubity nebo s více opakováními vrstev provázání a rotací mohou ukládat více parametrů, ale dělají to při větší hloubce obvodu. K hloubkám některých vestavěných feature map se vrátíme níže. Několik dalších metod kódování, které jsou zabudovány do Qiskitu, má jako součást svých názvů výraz „feature map". Připomeňme, že kódování dat do kvantového obvodu je mapování příznaků, v tom smyslu, že přenáší data do nového prostoru: Hilbertova prostoru příslušných qubitů. Vztah mezi dimenzionalitou původního prostoru příznaků a dimenzionalitou Hilbertova prostoru závisí na obvodu, který použiješ pro kódování.
Mapa příznaků
Mapa příznaků (ZFM) může být interpretována jako přirozené rozšíření fázového kódování. ZFM se skládá ze střídajících se vrstev jednoqubitových hradlo: vrstev Hadamardových hradlo a vrstev fázových hradlo. Nechť datový vektor má příznaků. Kvantový obvod, který provádí mapování příznaků, je reprezentován jako unitární operátor působící na počáteční stav:
kde je -qubitový základní stav. Tato notace se používá pro konzistenci s referencí [4] Havlicek et al. Příznaky dat jsou mapovány v poměru 1:1 na odpovídající qubity. Například pokud máš v datovém vektoru 8 příznaků, použiješ 8 qubitů. ZFM obvod se skládá z opakování podobvodu tvořeného vrstvami Hadamardových hradlo a vrstvami fázových hradlo. Hadamardova vrstva se skládá z Hadamardova hradlo působícího na každý qubit v -qubitovém registru, , ve stejné fázi algoritmu. Stejný popis platí i pro vrstvu fázových hradlo, ve které na qubit působí . Každý hradlo má jako argument jeden příznak, ale vrstva fázových hradlo () je funkcí datového vektoru. Unitární operátor celého ZFM obvodu s jedním opakováním je:
Pak opakování tohoto unitárního operátoru je
Datové příznaky jsou mapovány na fázové hradlo stejným způsobem ve všech opakováních. Stav feature map ZFM je produktový stav a je efektivní pro klasickou simulaci[4].
Začneme malým příkladem: dvouqubitový ZFM obvod je zakódován pomocí Qiskitu a vykreslen tak, aby zobrazoval jednoduchou strukturu obvodu. V příkladu je implementováno jedno opakování, , s datovým vektorem . Všimni si, že je to zapsáno ve standardním pořadí vektoru v Pythonu, což znamená, že prvek je Můžeme tento příznak zakódovat na náš qubit, nebo na náš Opět nemůže vždy existovat jediné mapování 1:1 z pořadí příznaků na pořadí qubitů, protože různé feature map kódují různé počty příznaků na každý qubit. Opět je důležité, abychom věděli, kde je každý příznak kódován. Při zadávání seznamu parametrů do feature map zakóduje příznak 0 ze seznamu na qubit s nejnižší hodnotou s parametrizovaným hradlo, tedy na qubit 0. Proto budeme tuto konvenci dodržovat i při ručním výpočtu. Zakódujeme na qubit a na qubit.
Unitární operátor ZFM obvodu působí na počáteční stav následujícím způsobem:
Vzorec byl přeskupen kolem tenzorového součinu, aby zdůraznil operace na každém qubitu. Následující kód v Qiskitu používá explicitně Hadamardovy a fázové hradlo, aby ukázal strukturu ZFM:
qc0 = QuantumCircuit(1)
qc1 = QuantumCircuit(1)
qc0.h(0)
qc0.p(pi / 2, 0)
qc1.h(0)
qc1.p(pi / 3, 0)
# Combine circuits qc0 and qc1 into 1 circuit
qc = QuantumCircuit(2)
qc.compose(qc0, [0], inplace=True)
qc.compose(qc1, [1], inplace=True)
qc.draw("mpl", scale=1)

Nyní zakódujeme stejný datový vektor do ZFM obvodu se třemi opakováními, , pomocí třídy Qiskit z_feature_map, což nám celkově dává kvantovou feature map . Ve třídě z_feature_map jsou parametry ve výchozím nastavení před mapováním na fázový hradlo násobeny 2, tedy . Abychom reprodukovali stejná kódování jako výše, vydělíme 2.
from qiskit.circuit.library import z_feature_map
zfeature_map = z_feature_map(feature_dimension=2, reps=3)
zfeature_map = zfeature_map.assign_parameters([(1 / 2) * pi / 2, (1 / 2) * pi / 3])
zfeature_map.decompose().draw("mpl")

Je zřejmé, že se jedná o jiné mapování než to, které bylo provedeno ručně výše, ale všimni si konzistentnosti v pořadí parametrů: bylo opět zakódováno na qubit.
ZFM můžeš použít prostřednictvím třídy ZFM v Qiskitu; tuto strukturu můžeš také využít jako inspiraci pro vytvoření vlastního mapování příznaků.
Mapa příznaků
Mapa příznaků (ZZFM) rozšiřuje ZFM o dvoukubitové entanglující hradlo, konkrétně o -rotační hradlo . Předpokládá se, že ZZFM je obecně náročná na výpočet na klasickém počítači, na rozdíl od ZFM.
implementuje -interakci a je maximálně entanglující pro . lze rozložit na sérii hradel na dvou qubitech, jak ukazuje následující kód v Qiskitu, který využívá hradlo RZZ a metodu třídy QuantumCircuit decompose. Zakódujeme jeden příznak datového vektoru :
qc = QuantumCircuit(2)
qc.rzz(pi, 0, 1)
qc.draw("mpl", scale=1)

Jak bývá zvykem, vidíme to jako jednu hradlo-like jednotku, dokud nepoužijeme .decompose(), abychom viděli všechny dílčí hradlo.
qc.decompose().draw("mpl", scale=1)

Data jsou mapována pomocí fázové rotace na druhém qubitu. hradlo entangluje dva qubity, na které působí, mírou entanglementu určenou hodnotou zakódovaného příznaku.
Celý obvod ZZFM se skládá z Hadamardovy hradlo a fázové hradlo, jako v ZFM, následovaných výše popsaným entanglementem. Jediná opakování obvod ZZFM je:
kde obsahuje vrstvu ZZ-hradlo strukturovanou schématem entanglementu. Několik schémat entanglementu je ukázáno v blocích kódu níže. Struktura také zahrnuje funkci, která kombinuje datové příznaky z qubitů entanglovaných následujícím způsobem. Řekněme, že hradlo má být aplikována na qubity a . Ve fázové vrstvě mají tyto qubity fázové hradlo, které na ně zakódují a . Argument hradlo nebude jednoduše jedním z těchto příznaků nebo druhým, ale funkcí, která se často označuje (nezaměňovat s azimutálním úhlem):
Toto uvidíme v několika příkladech níže. Rozšíření na více opakování je stejné jako v případě z_feature_map:
Protože operátory se zvýšily na složitosti, zakódujme nejprve datový vektor pomocí dvoukubitové ZZFM s jedním opakováním s použitím následujícího kódu:
from qiskit.circuit.library import zz_feature_map
feature_dim = 2
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose(reps=1).draw("mpl", scale=1)

Ve výchozím nastavení v Qiskitu jsou příznaky mapovány společně do touto mapovací funkcí . Qiskit umožňuje uživateli přizpůsobit funkci (nebo , kde je množina dvojic qubitů spojených přes hradlo ) jako krok předzpracování.
Přejdeme-li na čtyřrozměrný datový vektor a mapování na čtyřkubitovou ZZFM s jedním opakováním, začneme vidět mapování pro různé dvojice qubitů. Vidíme také význam „lineárního" entanglementu:
feature_dim = 4
zzfeature_map = zz_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1
)
zzfeature_map.decompose().draw("mpl", scale=1)

Ve schématu lineárního entanglementu jsou v tomto obvod entanglovány sousední (číslované) dvojice qubitů. V Qiskitu existují i jiná vestavěná schémata entanglementu, včetně circular a full.
Mapa příznaků Pauli
Mapa příznaků Pauli (PFM) je zobecněním ZFM a ZZFM pro použití libovolných Pauli hradlo. Mapa příznaků Pauli má velmi podobnou formu jako předchozí dvě feature map. Pro opakování kódování příznaků vektoru
V případě PFM je zobecněno na unitární operátor Pauliho rozkladu. Zde uvádíme obecnější formu feature map, které jsme dosud uvažovali:
kde je Pauliho operátor, . Zde je množina všech konektivit qubit, jak je určeno feature map, včetně množiny qubit, na které působí jednoqubitové hradlo. To znamená, že pro feature map, v níž na qubit 0 působil fázový hradlo a na qubit 2 a 3 působil hradlo , by množina obsahovala . prochází všemi prvky této množiny. V předchozích feature map byla funkce spojena buď výhradně s jednoqubitovými hradlo, nebo výhradně s dvouqubitovými hradlo. Zde ji definujeme obecně:
Dokumentaci najdeš v dokumentaci třídy Pauli feature map pro Qiskit). V ZZFM je operátor omezen na .
Jeden způsob, jak porozumět výše uvedenému unitárnímu operátoru, je analogie s propagátorem ve fyzikálním systému. Výše uvedený unitární operátor je operátor unitárního vývoje, , pro Hamiltonián, , podobný Isingovu modelu, kde je časový parametr, , nahrazen datovými hodnotami, které řídí vývoj. Rozvinutí tohoto unitárního operátoru dává obvod PFM. Propletenecké konektivity v lze interpretovat jako Isingova vazby ve spinové mřížce.
Uvažujme příklad Pauli operátorů a reprezentujících tyto interakce Isingova typu. Qiskit poskytuje třídu pauli_feature_map pro vytváření instancí PFM s volbou jednoqubitových a -qubitových hradlo, které budou v tomto příkladu předány jako Pauliho řetězce 'Y' a 'XX'. Typicky je rovno 1 nebo 2 pro jednoqubitové, respektive dvouqubitové interakce. Schéma propletení je „lineární", což znamená, že jsou vázány pouze sousední qubit v obvod. Všimni si, že to neodpovídá sousedním qubit na samotném kvantovém počítači, protože tento obvod je abstrakční vrstvou.
from qiskit.circuit.library import pauli_feature_map
feature_dim = 3
pfmap = pauli_feature_map(
feature_dimension=feature_dim, entanglement="linear", reps=1, paulis=["Y", "XX"]
)
pfmap.decompose().draw("mpl", scale=1.5)

Qiskit poskytuje parametr v Pauli feature map pro řízení škálování Pauliho rotací.
Výchozí hodnota je . Optimalizací její hodnoty v intervalu, například lze lépe přizpůsobit kvantové jádro datům.
Galerie map příznaků Pauli
Zde vizualizujeme různé Pauli feature mapy pro dvouqubitové obvody, abychom lépe pochopili rozsah možností.
from qiskit.visualization import circuit_drawer
import matplotlib.pyplot as plt
feature_dim = 2
fig, axs = plt.subplots(9, 2)
i_plot = 0
for paulis in [
["I"],
["X"],
["Y"],
["Z"],
["XX"],
["XY"],
["XZ"],
["YY"],
["YZ"],
["ZZ"],
["X", "ZZ"],
["Y", "ZZ"],
["Z", "ZZ"],
["X", "YZ"],
["Y", "YZ"],
["Z", "YZ"],
["YY", "ZZ"],
["XY", "ZZ"],
]:
pfmap = pauli_feature_map(feature_dimension=feature_dim, paulis=paulis, reps=1)
circuit_drawer(
pfmap.decompose(),
output="mpl",
style={"backgroundcolor": "#EEEEEE"},
ax=axs[int((i_plot - i_plot % 2) / 2), i_plot % 2],
)
axs[int((i_plot - i_plot % 2) / 2), i_plot % 2].title.set_text(paulis)
i_plot += 1
fig.set_figheight(16)
fig.set_figwidth(16)
Výše uvedené lze samozřejmě rozšířit o další permutace a opakování Pauliho matic. Doporučujeme ti s těmito možnostmi experimentovat.
Přehled vestavěných map příznaků
Viděl/a jsi několik schémat pro kódování dat do kvantového obvod:
- Basis encoding
- Amplitude encoding
- Angle encoding
- Phase encoding
- Dense encoding
Viděl/a jsi, jak sestavit vlastní feature map pomocí těchto kódovacích schémat, a viděl/a jsi čtyři vestavěné feature mapy, které využívají angle a phase encoding:
- Efficient SU2
- Z feature map
- ZZ feature map
- Pauli feature map
Tyto vestavěné feature mapy se od sebe lišily v několika ohledech:
- Hloubka pro daný počet zakódovaných příznaků
- Počet qubitů potřebných pro daný počet příznaků
- Míra provázání (úzce souvisí s ostatními rozdíly)
Níže uvedený kód aplikuje tyto čtyři vestavěné feature mapy na kódování sady příznaků a vykreslí hloubku dvou-qubitového obvod. Protože míry chyb dvou-qubitových hradlo jsou výrazně vyšší než u jednoho qubitu, může být nejdůležitější sledovat hloubku dvou-qubitových hradlo. V níže uvedeném kódu získáme počty všech hradlo v obvod tak, že nejprve obvod rozložíme a poté použijeme count_ops(), jak je ukázáno níže. Dvou-qubitové hradlo, o které nám jde, jsou zde hradlo 'cx':
# Initializing parameters and empty lists for depths
x = [0.1, 0.2]
n_data = []
zz2gates = []
su22gates = []
z2gates = []
p2gates = []
# Generating feature maps
for n in range(3, 10):
x.append(n / 10)
zzcircuit = zz_feature_map(n, reps=1, insert_barriers=True)
zcircuit = z_feature_map(n, reps=1, insert_barriers=True)
su2circuit = efficient_su2(n, reps=1, insert_barriers=True)
pcircuit = pauli_feature_map(n, reps=1, paulis=["XX"], insert_barriers=True)
# Getting the cx depths
zzcx = zzcircuit.decompose().count_ops().get("cx")
zcx = zcircuit.decompose().count_ops().get("cx")
su2cx = su2circuit.decompose().count_ops().get("cx")
pcx = pcircuit.decompose().count_ops().get("cx")
# Appending the cx gate counts to the lists. We shift the zz and Pauli data points,
# because they overlap.
n_data.append(n)
zz2gates.append(zzcx - 0.5)
z2gates.append(0)
su22gates.append(su2cx)
p2gates.append(pcx + 0.5)
# Plot the output
plt.plot(n_data, p2gates, "bo")
plt.plot(n_data, zz2gates, "ro")
plt.plot(n_data, su22gates, "yo")
plt.plot(n_data, z2gates, "go")
plt.ylabel("CX Gates")
plt.xlabel("Data elements")
plt.legend(["Pauli", "ZZ", "SU2", "Z"])
# plt.suptitle('zz_feature_map(n)')
plt.show()
Obecně platí, že Pauli a ZZ feature mapy mají za následek větší hloubku obvod a vyšší počet dvou-qubitových hradlo než efficient_su2 a Z feature mapy.
Protože feature mapy zabudované do Qiskitu mají široké uplatnění, nebude nutné navrhovat vlastní – zejména ve fázi učení. Odborníci na kvantové strojové učení se však k navrhování vlastních feature map pravděpodobně vrátí, až se budou potýkat se dvěma složitými výzvami:
-
Moderní hardware: přítomnost šumu a vysoká režie kódů pro opravu chyb znamenají, že současné aplikace budou muset brát v úvahu faktory jako efektivita hardware a minimalizace hloubky dvou-qubitových hradlo.
-
Mapování vhodná pro daný problém: Jednou věcí je říci, že
zz_feature_mapje například obtížně klasicky simulovatelná, a tedy zajímavá. Úplně jiná věc je, abyzz_feature_mapbyla ideálně vhodná pro tvůj úkol strojového učení nebo datovou sadu. Výkonnost různých parametrizovaných kvantových obvod na různých typech dat je aktivní oblastí výzkumu.
Uzavíráme poznámkou o hardwarové efektivitě.
Hardwarově efektivní mapování příznaků
Hardwarově efektivní feature map je taková, která zohledňuje omezení skutečných kvantových počítačů s cílem snížit šum a chyby ve výpočtu. Při spouštění kvantových obvod na kvantových počítačích blízké budoucnosti existuje mnoho strategií, jak zmírnit šum inherentní hardwaru. Jednou z hlavních strategií pro hardwarovou efektivitu je minimalizace hloubky kvantového obvod tak, aby šum a dekoherence měly méně času na narušení výpočtu. Hloubka kvantového obvod je počet časově zarovnaných kroků hradlo potřebných k dokončení celého výpočtu (po optimalizaci obvod)[5]. Připomeň si, že hloubka abstraktního, logického obvod může být mnohem nižší než hloubka po transpilaci pro skutečný kvantový počítač.
Transpilace je proces převodu kvantového obvod z vysokoúrovňové abstrakce na podobu připravenou ke spuštění na skutečném kvantovém počítači, přičemž zohledňuje omezení hardwaru. Kvantový počítač má nativní sadu jednoqubitových a dvouqubitových hradlo. To znamená, že všechny hradlo v kódu Qiskit musí být transpilovány do sady nativních hardwarových hradlo. Například v ibm_torino, QPU s procesorem Heron r1 dokončeném v roce 2023, jsou nativní nebo základní hradlo {CZ, ID, RZ, SX, X}. Jedná se o dvouqubitový hradlo řízený-Z a jednoqubitové hradlo nazývané identita, -rotace, druhá odmocnina NOT a NOT, které dohromady tvoří univerzální sadu. Při implementaci vícequbitových hradlo jako ekvivalentního podobvodu jsou vyžadovány fyzické dvouqubitové hradlo spolu s dalšími jednoqubitovými hradlo dostupnými v hardwaru. Navíc, k provedení dvouqubitového hradlo na páru qubit, které nejsou fyzicky propojeny, se přidávají hradlo SWAP pro přesunutí stavů qubit mezi qubity za účelem umožnění propojení, což vede k nevyhnutelnému prodloužení obvod. Pomocí argumentu optimization, který lze nastavit od 0 až po nejvyšší úroveň 3. Pro větší kontrolu a přizpůsobitelnost lze transpilační pipeline spravovat pomocí Qiskit Pass Manager. Další informace o transpilaci najdeš v dokumentaci Qiskit Transpiler.
V Havlicek et al. 2019 [2] autoři dosahují hardwarové efektivity mimo jiné použitím feature map , protože jde o expanzi druhého řádu (viz výše oddíl „feature map "). Expanze -tého řádu obsahuje -qubitové hradlo. Kvantové počítače IBM® nemají nativní -qubitové hradlo, kde , takže jejich implementace by vyžadovala rozklad na dvouqubitové hradlo CNOT dostupné v hardwaru. Druhým způsobem, jak autoři minimalizují hloubku, je volba topologie vazby , která se přímo mapuje na architekturu propojení. Dalším provedením optimalizace, které podnikají, je cílení na výkonnější, vhodně propojenou podstrukturu hardwaru. Dalšími věcmi, které je třeba zvážit, jsou minimalizace počtu opakování feature map a volba přizpůsobeného nízkoúrovňového nebo „lineárního" schématu propletení namísto „úplného" schématu, které proplétá všechny qubity.

Výše uvedená grafika zobrazuje síť uzlů a hran reprezentujících fyzické qubity a hardwarová propojení. Mapa propojení a výkon ibm_torino jsou zobrazeny se všemi možnými dvouqubitovými hradlo vazby CZ. qubity jsou barevně kódovány na škále na základě relaxačního času T1 v mikrosekundách (μs), přičemž delší časy T1 jsou lepší a jsou ve světlejším odstínu. Hrany propojení jsou barevně kódovány podle chyby CZ, přičemž tmavší odstíny jsou lepší. Informace o specifikaci hardwaru jsou dostupné ve schématu konfigurace hardwarového backendu IBMQBackend.configuration().
Reference
- Maria Schuld and Francesco Petruccione, Supervised Learning with Quantum Computers, Springer 2018, doi:10.1007/978-3-319-96424-9.
- Vojtech Havlicek et al., "Supervised Learning with Quantum Enhanced Feature Spaces." Nature, vol. 567 (2019): 209–212. https://arxiv.org/abs/1804.11326.
- Ryan LaRose and Brian Coyle, "Robust data encodings for quantum classifiers", Physical Review A 102, 032420 (2020), doi:10.1103/PhysRevA.102.032420, arXiv:2003.01695.
- Lou Grover and Terry Rudolph. "Creating Superpositions That Correspond to Efficiently Integrable Probability Distributions." arXiv:quant-ph/0208112, August 15, 2002, https://arxiv.org/abs/quant-ph/0208112.
- Adrián Pérez-Salinas, Alba Cervera-Lierta, Elies Gil-Fuster, José I. Latorre, "Data re-uploading for a universal quantum classifier", Quantum 4, 226 (2020), ArXiv.org/abs/1907.02085.
- Maria Schuld, Ryan Sweke, Johannes Jakob Meyer, "The effect of data encoding on the expressive power of variational quantum machine learning models", Phys. Rev. A 103, 032430 (2021), arxiv.org/abs/2008.08605
import qiskit
qiskit.version.get_version_info()