Příklady a aplikace
V této lekci prozkoumáme několik příkladů variačních algoritmů a způsoby jejich použití:
- Jak napsat vlastní variační algoritmus
- Jak použít variační algoritmus k nalezení minimálních vlastních hodnot
- Jak využít variační algoritmy k řešení praktických aplikačních případů
Všimni si, že rámec Qiskit patterns lze aplikovat na všechny problémy, které zde představíme. Abychom se však vyhnuli opakování, budeme kroky rámce explicitně uvádět pouze v jednom příkladě, spuštěném na skutečném hardwaru.
Definice problémů
Představ si, že chceme použít variační algoritmus k nalezení vlastní hodnoty následujícího pozorovatelné veličiny:
Tato pozorovatelná veličina má následující vlastní hodnoty:
A vlastní stavy:
# Added by doQumentation — required packages for this notebook
!pip install -q numpy qiskit qiskit-ibm-runtime rustworkx scipy
from qiskit.quantum_info import SparsePauliOp
observable_1 = SparsePauliOp.from_list([("II", 2), ("XX", -2), ("YY", 3), ("ZZ", -3)])
Vlastní VQE
Nejprve prozkoumáme, jak ručně sestavit instanci VQE k nalezení nejnižší vlastní hodnoty pro . Využijeme přitom různé techniky, které jsme probírali v průběhu tohoto kurzu.
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
return cost
from qiskit.circuit.library.n_local import n_local
from qiskit import QuantumCircuit
import numpy as np
reference_circuit = QuantumCircuit(2)
reference_circuit.x(0)
variational_form = n_local(
num_qubits=2,
rotation_blocks=["rz", "ry"],
entanglement_blocks="cx",
entanglement="linear",
reps=1,
)
raw_ansatz = reference_circuit.compose(variational_form)
raw_ansatz.decompose().draw("mpl")
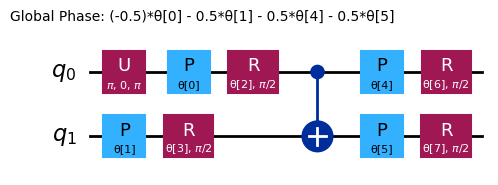
Začneme laděním na lokálních simulátorech.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Nyní nastavíme počáteční sadu parametrů:
x0 = np.ones(raw_ansatz.num_parameters)
print(x0)
[1. 1. 1. 1. 1. 1. 1. 1.]
Minimalizací této účelové funkce můžeme vypočítat optimální parametry
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe,
x0,
args=(raw_ansatz, observable_1, estimator),
method="COBYLA",
options={"maxiter": 1000, "disp": True},
)
end_time = time.time()
execution_time = end_time - start_time
Return from COBYLA because the trust region radius reaches its lower bound.
Number of function values = 103 Least value of F = -5.999999998357189
The corresponding X is:
[2.27483579e+00 8.37593091e-01 1.57080508e+00 5.82932911e-06
2.49973063e+00 6.41884255e-01 6.33686904e-01 6.33688223e-01]
result
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -5.999999998357189
x: [ 2.275e+00 8.376e-01 1.571e+00 5.829e-06 2.500e+00
6.419e-01 6.337e-01 6.337e-01]
nfev: 103
maxcv: 0.0
Protože tento jednoduchý problém používá pouze dva qubity, můžeme výsledek ověřit pomocí NumPy lineárního algebraického řešiče vlastních hodnot.
from numpy.linalg import eigvalsh
solution_eigenvalue = min(eigvalsh(observable_1.to_matrix()))
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((result.fun - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Number of iterations: 103
Time (s): 0.4394676685333252
Percent error: 2.74e-08
Jak vidíš, výsledek je velmi blízký ideální hodnotě.
Experimentování pro zlepšení rychlosti a přesnosti
Přidání referenčního stavu
V předchozím příkladu jsme nepoužili žádný referenční operátor . Teď se zamysli nad tím, jak lze získat ideální vlastní stav . Uvažuj následující obvod.
from qiskit import QuantumCircuit
ideal_qc = QuantumCircuit(2)
ideal_qc.h(0)
ideal_qc.cx(0, 1)
ideal_qc.draw("mpl")

Můžeme rychle ověřit, že tento obvod nám dává požadovaný stav.
from qiskit.quantum_info import Statevector
Statevector(ideal_qc)
Statevector([0.70710678+0.j, 0. +0.j, 0. +0.j,
0.70710678+0.j],
dims=(2, 2))
Nyní, když jsme viděli, jak vypadá obvod připravující řešení, zdá se rozumné použít jako referenční obvod Hadamardovu bránu, takže celý ansatz se stane:
reference = QuantumCircuit(2)
reference.h(0)
reference.cx(0, 1)
# Include barrier to separate reference from variational form
reference.barrier()
ref_ansatz = variational_form.decompose().compose(reference, front=True)
ref_ansatz.draw("mpl")
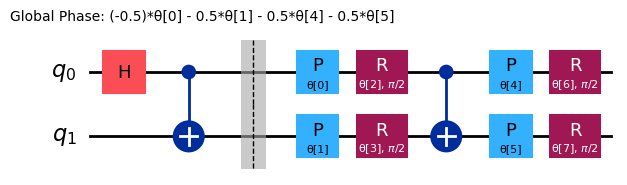
Pro tento nový obvod by bylo možné dosáhnout ideálního řešení, když jsou všechny parametry nastaveny na , což potvrzuje, že volba referenčního obvodu je rozumná.
Nyní porovnejme počet vyhodnocení účelové funkce, iterací optimalizátoru a čas potřebný oproti předchozímu pokusu.
import time
start_time = time.time()
ref_result = minimize(
cost_func_vqe, x0, args=(ref_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
Pomocí optimálních parametrů vypočítáme minimální vlastní hodnotu:
experimental_min_eigenvalue_ref = cost_func_vqe(
ref_result.x, ref_ansatz, observable_1, estimator
)
print(experimental_min_eigenvalue_ref)
-5.999999996759607
print("ADDED REFERENCE STATE:")
print(f"""Number of iterations: {ref_result.nfev}""")
print(f"""Time (s): {execution_time}""")
print(
f"Percent error: {100*abs((experimental_min_eigenvalue_ref - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
ADDED REFERENCE STATE:
Number of iterations: 127
Time (s): 0.5620882511138916
Percent error: 5.40e-08
V závislosti na tvém konkrétním systému to může nebo nemusí vést ke zlepšení rychlosti či přesnosti v tomto velmi malém příkladu. Podstatné je, že začínání s fyzikálně motivovanými referenčními stavy je čím dál důležitější pro zlepšení rychlosti a přesnosti, jak problémy rostou.
Změna počátečního bodu
Nyní, když jsme viděli vliv přidání referenčního stavu, se podíváme na to, co se stane, když zvolíme různé počáteční body . Konkrétně použijeme a .
Pamatuj, že — jak bylo popsáno při představení referenčního stavu — ideální řešení by bylo nalezeno, když jsou všechny parametry , takže první počáteční bod by měl vést k menšímu počtu vyhodnocení.
import time
start_time = time.time()
x0 = [0, 0, 0, 0, 6, 0, 0, 0]
x0_1_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 1:")
print(f"""Number of iterations: {x0_1_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 1:
Number of iterations: 108
Time (s): 0.4492197036743164
Nastavení počátečního bodu na :
import time
start_time = time.time()
x0 = 6 * np.ones(raw_ansatz.num_parameters)
x0_2_result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
print("INITIAL POINT 2:")
print(f"""Number of iterations: {x0_2_result.nfev}""")
print(f"""Time (s): {execution_time}""")
INITIAL POINT 2:
Number of iterations: 107
Time (s): 0.40889453887939453
Experimentováním s různými počátečními body můžeš dosáhnout konvergence rychleji a s menším počtem vyhodnocení funkce.
Experimentování s různými optimalizátory
Optimalizátor můžeme upravit pomocí argumentu method funkce minimize ze SciPy, přičemž více možností najdeš zde. Původně jsme použili omezený minimalizátor (COBYLA). V tomto příkladu prozkoumáme použití neomezeného minimalizátoru (BFGS).
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(raw_ansatz, observable_1, estimator), method="BFGS"
)
end_time = time.time()
execution_time = end_time - start_time
print("CHANGED TO BFGS OPTIMIZER:")
print(f"""Number of iterations: {result.nfev}""")
print(f"""Time (s): {execution_time}""")
CHANGED TO BFGS OPTIMIZER:
Number of iterations: 117
Time (s): 0.31656408309936523
VQD příklad
Zde implementujeme framework Qiskit patterns explicitně.
Krok 1: Mapování klasických vstupů na kvantový problém
Nyní místo hledání pouze nejnižší vlastní hodnoty našich pozorovatelných veličin budeme hledat všechny , (kde ).
Pamatuj si, že účelové funkce VQD jsou:
To je obzvláště důležité, protože vektor (v tomto případě ) musí být předán jako argument při definování objektu VQD.
Také v implementaci VQD v Qiskitu se místo uvažování efektivních pozorovatelných veličin popsaných v předchozím notebooku věrnosti počítají přímo pomocí algoritmu ComputeUncompute, který využívá primitiv Sampler k vzorkování pravděpodobnosti získání pro obvod
. To funguje právě proto, že tato pravděpodobnost je
ansatz = n_local(
num_qubits=2,
rotation_blocks=["ry", "rz"],
entanglement_blocks="cz",
# entanglement="linear",
reps=1,
)
ansatz.decompose().draw("mpl")
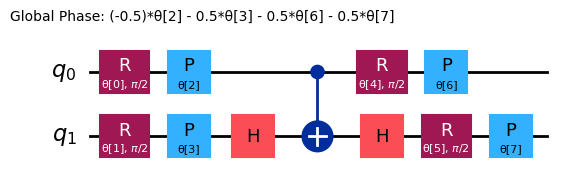
Začněme tím, že se podíváme na následující pozorovatelnou veličinu:
Tato pozorovatelná veličina má následující vlastní hodnoty:
A vlastní stavy:
from qiskit.quantum_info import SparsePauliOp
observable_2 = SparsePauliOp.from_list([("II", 2), ("XX", -3), ("YY", 2), ("ZZ", -4)])
K výpočtu penalizace za překryv použijeme následující funkci. Všimni si, že to je stále součástí mapování problému na kvantové obvody. Nicméně, jak bylo probráno v předchozí lekci, tato funkce počítá překryv mezi aktuálním variačním obvodem a optimalizovaným obvodem z předchozího, energeticky nižšího/nákladově nižšího stavu. Nový generovaný obvod musí být také transpilován, aby mohl běžet na skutečném hardwaru. Tuto funkci jsme již viděli, použitou na simulátoru. Zde musíme již zohlednit transpilaci a související optimalizaci pro případ, kdy použijeme skutečný backend, proto jsou tam řádky kolem if realbackend == 1. Tím trochu míchám krok 2, ale krok 2 explicitně vyznačíme později.
import numpy as np
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
def calculate_overlaps(
ansatz, prev_circuits, parameters, sampler, realbackend, backend
):
def create_fidelity_circuit(circuit_1, circuit_2):
if len(circuit_1.clbits) > 0:
circuit_1.remove_final_measurements()
if len(circuit_2.clbits) > 0:
circuit_2.remove_final_measurements()
circuit = circuit_1.compose(circuit_2.inverse())
circuit.measure_all()
return circuit
overlaps = []
for prev_circuit in prev_circuits:
fidelity_circuit = create_fidelity_circuit(ansatz, prev_circuit)
if realbackend == 1:
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
fidelity_circuit = pm.run(fidelity_circuit)
sampler_job = sampler.run([(fidelity_circuit, parameters)])
meas_data = sampler_job.result()[0].data.meas
counts_0 = meas_data.get_int_counts().get(0, 0)
shots = meas_data.num_shots
overlap = counts_0 / shots
overlaps.append(overlap)
return np.array(overlaps)
Nyní přidáme účelovou funkci VQD. Všimni si, že oproti předchozí lekci máme nyní dva další argumenty (realbackend a backend), které nám pomáhají s transpilací při použití skutečných backendů.
def cost_func_vqd(
parameters,
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
hamiltonian,
realbackend,
backend,
):
estimator_job = estimator.run([(ansatz, hamiltonian, [parameters])])
total_cost = 0
if step > 1:
overlaps = calculate_overlaps(
ansatz, prev_states, parameters, sampler, realbackend, backend
)
total_cost = np.sum(
[np.real(betas[state] * overlap) for state, overlap in enumerate(overlaps)]
)
estimator_result = estimator_job.result()[0]
value = estimator_result.data.evs[0] + total_cost
return value
Opět použijeme simulátory pro ladění a poté přejdeme na skutečný hardware.
from qiskit.primitives import StatevectorSampler
from qiskit.primitives import StatevectorEstimator
sampler = StatevectorSampler(default_shots=4092)
estimator = StatevectorEstimator()
Zde zavádíme počet stavů, které chceme vypočítat, penalizace a sadu počátečních parametrů x0.
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = [50, 60, 40]
x0 = np.ones(8)
Nyní otestujeme algoritmus pomocí simulátorů:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"maxiter": 200, "tol": 0.000001},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.9999999999996
x: [ 1.571e+00 1.571e+00 2.519e+00 2.100e+00 1.242e+00
6.935e-01 2.298e+00 1.991e+00]
nfev: 151
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 3.698974255258432
x: [ 1.269e+00 1.109e+00 1.080e+00 1.200e+00 1.094e+00
1.163e+00 9.752e-01 9.519e-01]
nfev: 103
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 4.731320121938101
x: [ 1.533e+00 2.451e+00 2.526e+00 2.406e+00 1.968e+00
2.105e+00 8.537e-01 8.442e-01]
nfev: 110
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 7.008239313655201
x: [ 4.150e+00 2.120e+00 3.495e+00 7.262e-01 1.953e+00
-1.982e-01 3.263e-01 2.563e+00]
nfev: 126
maxcv: 0.0
eigenvalues
[np.float64(-6.9999999999996),
np.float64(3.698974255258432),
np.float64(4.731320121938101),
np.float64(7.008239313655201)]
Tyto výsledky jsou poměrně blízko očekávaným, s výjimkou chyby aproximace a globální fáze. Mohli bychom upravit toleranci klasického optimalizátoru a/nebo penalizace za překryv stavových vektorů, abychom získali přesnější hodnoty.
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 5.71e-14
Percent error: 2.33e-01
Percent error: 5.37e-02
Percent error: 1.18e-03
Změna betas
Jak bylo zmíněno v předchozí lekci, hodnoty by měly být větší než rozdíl mezi vlastními hodnotami. Podívejme se, co se stane, když tuto podmínku nesplňují pro
s vlastními hodnotami
from qiskit.quantum_info import SparsePauliOp
k = 4
betas = np.ones(3)
x0 = np.zeros(8)
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
observable_2,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.01, "maxiter": 200},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -6.999916534745094
x: [ 1.568e+00 -1.569e+00 1.385e-01 1.398e-01 -7.972e-01
7.835e-01 -2.375e-01 4.539e-02]
nfev: 125
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -1.515139929812874
x: [-5.317e-04 -2.514e-03 1.016e+00 9.998e-01 3.890e-04
1.772e-04 1.568e-04 8.497e-04]
nfev: 35
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: -0.509948114293115
x: [-3.796e-03 8.853e-03 3.015e-04 9.997e-01 6.271e-04
-2.554e-03 1.017e-04 2.766e-04]
nfev: 37
maxcv: 0.0
message: Return from COBYLA because the trust region radius reaches its lower bound.
success: True
status: 0
fun: 0.4914672235935682
x: [-7.178e-03 -8.652e-03 1.125e+00 -5.428e-02 -1.586e-03
2.031e-03 -3.462e-03 5.734e-03]
nfev: 35
maxcv: 0.0
solution_eigenvalues = [-7, 3, 5, 7]
for index, experimental_eigenvalue in enumerate(eigenvalues):
solution_eigenvalue = solution_eigenvalues[index]
print(
f"Percent error: {abs((experimental_eigenvalue - solution_eigenvalue)/solution_eigenvalue):.2e}"
)
Percent error: 1.19e-05
Percent error: 1.51e+00
Percent error: 1.10e+00
Percent error: 9.30e-01
Tentokrát optimalizátor vrátí stejný stav jako navrhované řešení pro všechny vlastní stavy: což je zjevně špatně. To se děje proto, že hodnoty betas byly příliš malé, aby penalizovaly minimální vlastní stav v následných nákladových funkcích. Proto nebyl vyloučen z efektivního prohledávaného prostoru v pozdějších iteracích algoritmu a byl vždy zvolen jako nejlepší možné řešení.
Doporučujeme experimentovat s hodnotami a zajistit, aby byly větší než rozdíl mezi vlastními hodnotami.
Krok 2: Optimalizace problému pro kvantové spuštění
Pro spuštění na skutečném hardwaru musíme optimalizovat kvantové obvody pro náš vybraný kvantový počítač. Pro naše účely zde jednoduše použijeme nejméně zaneprázdněný backend.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
# Or use a specific backend
# backend = service.backend("ibm_brisbane")
print(backend)
<IBMBackend('ibm_brisbane')>
Náš obvod transpilujeme pomocí přednastavené správy průchodů (preset pass manager) s úrovní optimalizace 3.
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = observable_2.apply_layout(layout=isa_ansatz.layout)
Krok 3: Spuštění pomocí primitiv Qiskitu
S hodnotami betas resetovanými na dostatečně vysoké hodnoty nyní můžeme spustit výpočet na skutečném kvantovém hardwaru.
# Estimated compute resource usage: 25 minutes.
# Benchmarked at 24 min, 30 sec on an Eagle r3 processor on 5-30-24
k = 2
betas = [30, 50, 80]
x0 = np.zeros(8)
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=10_000)
with Session(backend=backend) as session:
estimator = Estimator(mode=session, options=estimator_options)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(isa_ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"maxiter": 200},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Krok 4: Post-processing, vrácení výsledku v klasickém formátu
Náš výstup je strukturálně podobný tomu, co bylo probráno v předchozích lekcích a příkladech. Ale ve výsledcích výše je něco problematického, z čeho můžeme odvodit varovné poučení pro kontext excitovaných stavů. Abychom omezili výpočetní čas použitý v tomto výukovém příkladu, nastavili jsme maximální počet iterací pro klasický optimalizátor, který byl potenciálně příliš nízký: 200 iterací. Předchozí výpočet výše, na simulátoru, se nepodařilo konvergovat za 200 iterací. Náš zde konvergoval... ale s jakou tolerancí? Neurčili jsme toleranci, při které by COBYLA považoval sám sebe za „konvergovaný". Pohled na hodnotu funkce a srovnání s předchozími spuštěními nám říká, že COBYLA nebyl blízko konvergenci s přesností, kterou požadujeme.
Existuje ještě jeden problém: energie prvního excitovaného stavu se zdá být nižší než energie základního stavu! Pokus se vysvětlit, jak by se to mohlo stát. Nápověda: souvisí to s bodem konvergence, který jsme právě zmínili. Toto chování je podrobně vysvětleno níže po aplikaci VQD na molekulu H2.
Kvantová chemie: řešič základního stavu a excitovaných energií
Naším cílem je minimalizovat střední hodnotu pozorovatelné veličiny reprezentující energii (hamiltonián ):
from qiskit.quantum_info import SparsePauliOp
from qiskit.circuit.library import efficient_su2
H2_op = SparsePauliOp.from_list(
[
("II", -1.052373245772859),
("IZ", 0.39793742484318045),
("ZI", -0.39793742484318045),
("ZZ", -0.01128010425623538),
("XX", 0.18093119978423156),
]
)
chem_ansatz = efficient_su2(H2_op.num_qubits)
chem_ansatz.decompose().draw("mpl")
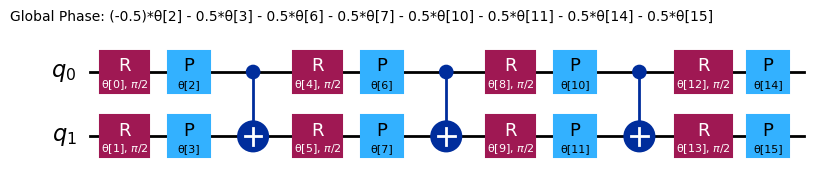
from qiskit import QuantumCircuit
def cost_func_vqe(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
Nyní nastavíme počáteční sadu parametrů:
import numpy as np
x0 = np.ones(chem_ansatz.num_parameters)
Tuto účelovou funkci můžeme minimalizovat, abychom vypočítali optimální parametry. Nejdřív si kód ověříme na lokálním simulátoru.
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
# SciPy minimizer routine
from scipy.optimize import minimize
import time
start_time = time.time()
result = minimize(
cost_func_vqe, x0, args=(chem_ansatz, H2_op, estimator), method="COBYLA"
)
end_time = time.time()
execution_time = end_time - start_time
result
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.857275029048451
x: [ 7.326e-01 1.354e+00 ... 1.040e+00 1.508e+00]
nfev: 242
maxcv: 0.0
Minimální hodnota účelové funkce (-1,857...) je energie základního stavu molekuly H2 v jednotkách hartree.
Excitované stavy
Pomocí VQD můžeme také vyřešit celkových stavů (základní stav a první excitovaný stav).
from qiskit.quantum_info import SparsePauliOp
import numpy as np
k = 2
betas = [33, 33]
# x0 = np.zeros(ansatz.num_parameters)
x0 = [
1.164e00,
-2.438e-01,
9.358e-04,
6.745e-02,
1.990e00,
9.810e-02,
6.154e-01,
5.454e-01,
]
Přidáme výpočet překryvu:
from scipy.optimize import minimize
prev_states = []
prev_opt_parameters = []
eigenvalues = []
realbackend = 0
for step in range(1, k + 1):
if step > 1:
prev_states.append(ansatz.assign_parameters(prev_opt_parameters))
result = minimize(
cost_func_vqd,
x0,
args=(
ansatz,
prev_states,
step,
betas,
estimator,
sampler,
H2_op,
realbackend,
None,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 2000},
)
print(result)
prev_opt_parameters = result.x
eigenvalues.append(result.fun)
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.8572671093941977
x: [ 1.164e+00 -2.437e-01 2.118e-03 6.448e-02 1.990e+00
9.870e-02 6.167e-01 5.476e-01]
nfev: 58
maxcv: 0.0
message: Optimization terminated successfully.
success: True
status: 1
fun: -1.0322873777662176
x: [ 3.205e+00 1.502e+00 1.699e+00 -1.107e-02 3.086e+00
1.530e+00 4.445e-02 7.013e-02]
nfev: 99
maxcv: 0.0
eigenvalues
[-1.8572671093941977, -1.0322873777662176]
Reálný hardware a závěrečné varování
Abychom to mohli spustit na reálném hardwaru, musíme kvantové obvody optimalizovat pro náš konkrétní kvantový počítač. Pro naše účely použijeme jednoduše nejméně vytížený backend.
from qiskit_ibm_runtime import SamplerV2 as Sampler
from qiskit_ibm_runtime import EstimatorV2 as Estimator
from qiskit_ibm_runtime import Session, EstimatorOptions
from qiskit_ibm_runtime import QiskitRuntimeService
service = QiskitRuntimeService()
backend = service.least_busy(operational=True, simulator=False)
Pro transpilaci použijeme přednastavený správce průchodů a náš obvod maximálně optimalizujeme pomocí úrovně optimalizace 3.
from qiskit.transpiler.preset_passmanagers import generate_preset_pass_manager
pm = generate_preset_pass_manager(backend=backend, optimization_level=3)
isa_ansatz = pm.run(ansatz)
isa_observable = H2_op.apply_layout(layout=isa_ansatz.layout)
Protože VQD je vysoce iterativní, provedeme všechny kroky uvnitř Runtime session, takže naše úlohy budou zařazeny do fronty pouze na začátku, a ne mezi každou aktualizací parametrů. Syntaxe účelové funkce ani estimátoru se nijak nemění.
x0 = [
1.306e00,
-2.284e-01,
6.913e-02,
-2.530e-02,
1.849e00,
7.433e-02,
6.366e-01,
5.600e-01,
]
# Estimated hardware usage: 20 min benchmarked on an Eagle r3 processor on 5-30-24
real_prev_states = []
real_prev_opt_parameters = []
real_eigenvalues = []
realbackend = 1
estimator_options = EstimatorOptions(resilience_level=1, default_shots=4096)
with Session(backend=backend) as session:
estimator = Estimator(mode=session)
sampler = Sampler(mode=session)
for step in range(1, k + 1):
if step > 1:
real_prev_states.append(
isa_ansatz.assign_parameters(real_prev_opt_parameters)
)
result = minimize(
cost_func_vqd,
x0,
args=(
isa_ansatz,
real_prev_states,
step,
betas,
estimator,
sampler,
isa_observable,
realbackend,
backend,
),
method="COBYLA",
options={"tol": 0.001, "maxiter": 300},
)
print(result)
real_prev_opt_parameters = result.x
real_eigenvalues.append(result.fun)
session.close()
print(real_eigenvalues)
Získaná energie základního stavu (-1,83 hartree) není příliš vzdálená od správné hodnoty (-1,85 hartree). Energie excitovaného stavu se však poměrně výrazně liší. Jde o podobné chybné chování, které jsme viděli dříve v této lekci. Energie excitovaného stavu je téměř stejná jako energie základního stavu. V předchozím případě jsme dokonce viděli energii excitovaného stavu, která byla nižší než nahlášená energie základního stavu.
U variačního výpočtu není možné získat energii nižší, než je skutečná energie základního stavu. V dřívějším případě nebyla námi získaná energie základního stavu příliš blízká skutečnému základnímu stavu. Protože jsme v tom případě skutečnou energii základního stavu nezískali, žádný rozpor neexistuje. V aktuálním případě byla energie základního stavu poměrně blízká správné hodnotě, a přesto se energie excitovaného stavu zdá podezřele blízká téže hodnotě.
Abychom lépe pochopili, jak k tomu došlo, připomeňme si, že excitovaný stav nalézáme tak, že požadujeme, aby byl variační stav ortogonální k základnímu stavu (pomocí překryvových obvodů a penalizačních členů). Pokud nezískáme přesnou energii základního stavu (nebo se mýlíme o pár procent), nezískáme ani přesný vektor základního stavu! Takže když požadujeme, aby byl excitovaný stav ortogonální k prvnímu nalezenému stavu, nevynucujeme ortogonalitu ke skutečnému základnímu stavu, ale k jeho nějaké aproximaci (někdy dosti nepřesné). Excitovaný stav tak nebyl nucen být ortogonální ke skutečnému základnímu stavu a naše odhady energií excitovaných stavů byly ve skutečnosti velmi blízké energii základního stavu.
Toto bude u VQD vždy problémem. V principu to však lze napravit zvýšením maximálního počtu iterací klasického optimalizátoru, zavedením nižší tolerance pro klasický optimalizátor, a případně také vyzkoušením jiného ansatzu, pokud opakovaně míjíme skutečný základní stav. Jak jsme viděli, může být také nutné upravit penalizace za překryv (betas). To je ale vlastně samostatný problém. Žádná penalizace za překryv tě nezachrání před přiblížením k základnímu stavu, pokud jsi nenašel dobrý odhad skutečného základního stavu pro překryvový obvod.
Optimalizace: Max-Cut
Problém maximálního řezu (Max-Cut) je kombinatorický optimalizační problém, který spočívá v rozdělení vrcholů grafu do dvou disjunktních množin tak, aby byl maximalizován počet hran mezi těmito dvěma množinami. Formálněji: pro daný neorientovaný graf , kde je množina vrcholů a je množina hran, se problém Max-Cut ptá, jak rozdělit vrcholy do dvou disjunktních podmnožin a tak, aby byl maximalizován počet hran, jejichž jeden koncový bod leží v a druhý v .
Max-Cut lze použít k řešení různých problémů, jako jsou shlukování, návrh sítí a fázové přechody. Začneme vytvořením grafu problému:
import rustworkx as rx
from rustworkx.visualization import mpl_draw
n = 4
G = rx.PyGraph()
G.add_nodes_from(range(n))
# The edge syntax is (start, end, weight)
edges = [(0, 1, 1.0), (0, 2, 1.0), (0, 3, 1.0), (1, 2, 1.0), (2, 3, 1.0)]
G.add_edges_from(edges)
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color="#1192E8"
)

Tento problém lze vyjádřit jako binární optimalizační problém. Pro každý uzel , kde je počet uzlů grafu (v tomto případě ), uvažujeme binární proměnnou . Tato proměnná bude mít hodnotu , pokud uzel patří do skupiny označené jako , a hodnotu , pokud patří do druhé skupiny označené jako . Dále označíme jako (prvek matice sousednosti ) váhu hrany vedoucí z uzlu do uzlu . Protože je graf neorientovaný, platí . Náš problém pak formulujeme jako maximalizaci následující účelové funkce:
Abychom tento problém mohli řešit na kvantovém počítači, vyjádříme účelovou funkci jako střední hodnotu pozorovatelné veličiny. Pozorovatelné, které Qiskit nativně přijímá, se však skládají z Pauliho operátorů s vlastními hodnotami a místo a . Proto provedeme následující změnu proměnné:
Kde . Pro pohodlný přístup k vahám všech hran použijeme matici sousednosti . Ta bude použita k získání naší účelové funkce:
Z toho plyne:
Nová účelová funkce, kterou chceme maximalizovat, je:
Navíc kvantový počítač přirozeně hledá minima (obvykle nejnižší energii) místo maxim, takže místo maximalizace budeme minimalizovat:
Nyní, když máme účelovou funkci k minimalizaci, jejíž proměnné mohou nabývat hodnot a , můžeme udělat následující analogii s Pauliho operátorem :
Jinými slovy, proměnná bude ekvivalentní bráně působící na qubit . Navíc:
Pozorovatelná veličina, kterou budeme uvažovat, je:
ke které bude třeba následně přičíst nezávislý člen:
Operátor je lineární kombinací členů s operátory Z na uzlech spojených hranou (připomeňme, že 0. qubit je nejvíce vpravo): . Po sestavení operátoru lze ansatz pro algoritmus QAOA snadno zkonstruovat pomocí obvodu QAOAAnsatz z knihovny obvodů Qiskit.
from qiskit.circuit.library import QAOAAnsatz
from qiskit.quantum_info import SparsePauliOp
max_hamiltonian = SparsePauliOp.from_list(
[("IIZZ", 1), ("IZIZ", 1), ("IZZI", 1), ("ZIIZ", 1), ("ZZII", 1)]
)
max_ansatz = QAOAAnsatz(max_hamiltonian, reps=2)
# Draw
max_ansatz.decompose(reps=3).draw("mpl")

# Sum the weights, and divide by 2
offset = -sum(edge[2] for edge in edges) / 2
print(f"""Offset: {offset}""")
Offset: -2.5
def cost_func(params, ansatz, hamiltonian, estimator):
"""Return estimate of energy from estimator
Parameters:
params (ndarray): Array of ansatz parameters
ansatz (QuantumCircuit): Parameterized ansatz circuit
hamiltonian (SparsePauliOp): Operator representation of Hamiltonian
estimator (Estimator): Estimator primitive instance
Returns:
float: Energy estimate
"""
pub = (ansatz, hamiltonian, params)
cost = estimator.run([pub]).result()[0].data.evs
# cost = estimator.run(ansatz, hamiltonian, parameter_values=params).result().values[0]
return cost
from qiskit.primitives import StatevectorEstimator as Estimator
from qiskit.primitives import StatevectorSampler as Sampler
estimator = Estimator()
sampler = Sampler()
Nyní nastavíme počáteční sadu náhodných parametrů:
import numpy as np
x0 = 2 * np.pi * np.random.rand(max_ansatz.num_parameters)
print(x0)
[6.0252949 0.58448176 2.15785731 1.13646074]
Ke minimalizaci účelové funkce lze použít libovolný klasický optimalizátor. Na reálném kvantovém systému si obvykle lépe vedou optimalizátory navržené pro nerovnoměrné krajiny účelových funkcí. Zde používáme rutinu COBYLA ze SciPy prostřednictvím funkce minimize.
Protože iterativně provádíme mnoho volání do Runtime, využíváme session, aby se všechna volání vykonala v jednom bloku. Navíc pro QAOA je řešení zakódováno ve výstupním rozdělení pravděpodobnosti ansatzového obvodu svázaného s optimálními parametry z minimalizace. Proto budeme potřebovat primitiv Sampler, který vytvoříme se stejnou session. A spustíme naši minimalizační rutinu:
result = minimize(
cost_func, x0, args=(max_ansatz, max_hamiltonian, estimator), method="COBYLA"
)
print(result)
message: Optimization terminated successfully.
success: True
status: 1
fun: -2.585287311689236
x: [ 7.332e+00 3.904e-01 2.045e+00 1.028e+00]
nfev: 80
maxcv: 0.0
Vektor parametrových úhlů (x) po dosazení do ansatzového obvodu dává hledané rozdělení grafu.
eigenvalue = cost_func(result.x, max_ansatz, max_hamiltonian, estimator)
print(f"""Eigenvalue: {eigenvalue}""")
print(f"""Max-Cut Objective: {eigenvalue + offset}""")
Eigenvalue: -2.585287311689236
Max-Cut Objective: -5.085287311689235
from qiskit.result import QuasiDistribution
from qiskit.primitives import StatevectorSampler
sampler = StatevectorSampler()
# Assign solution parameters to ansatz
qc = max_ansatz.assign_parameters(result.x)
# Add measurements to our circuit
qc.measure_all()
# Sample ansatz at optimal parameters
# samp_dist = sampler.run(qc).result().quasi_dists[0]
shots = 1024
job = sampler.run([qc], shots=shots)
qc.decompose().draw("mpl")

data_pub = job.result()[0].data
bitstrings = data_pub.meas.get_bitstrings()
counts = data_pub.meas.get_counts()
quasi_dist = QuasiDistribution(
{outcome: freq / shots for outcome, freq in counts.items()}
)
probabilities = quasi_dist
# Close the session since we are now done with it
# session.close()
from qiskit.visualization import plot_distribution
plot_distribution(counts)

binary_string = max(counts.items(), key=lambda kv: kv[1])[0]
x = np.asarray([int(y) for y in reversed(list(binary_string))])
colors = ["r" if x[i] == 0 else "c" for i in range(n)]
mpl_draw(
G, pos=rx.shell_layout(G), with_labels=True, edge_labels=str, node_color=colors
)

Shrnutí
V této lekci ses naučil(a):
- Jak napsat vlastní variační algoritmus
- Jak použít variační algoritmus k nalezení minimálních vlastních hodnot
- Jak využít variační algoritmy k řešení praktických aplikačních problémů